QinCodec: Neural Audio Compression with Implicit Neural Codebooks
In this paper, we challenge the common practice of training neural audio codecs end-to-end, instead proposing a three-stages strategy that allows us to rely on an implicit neural quantization layer for neural audio coding.
We propose QINCODEC, a 44.1 kHz audio codec based on the decoupled training of an autoencoder and a neural residual vector quantizer QINCO2, trained offline.
Our model is the first auto-encoder that relies on Vocos [Siuzdak, 2024] blocks, providing a lightweight and fast way to encode/decode audio, making its integration easy into the training pipelines of generative models.
QINCODEC outperforms state-of-the-art methods at 16 kbps bitrate and achieves competitive results at lower bitrates with both objective and subjective metrics.
Our offline approach offers a simple yet robust framework that allows to consider any off-the-shelf quantizer with a fixed pre-trained autoencoder, paving the way for adaptable and frugal codec design
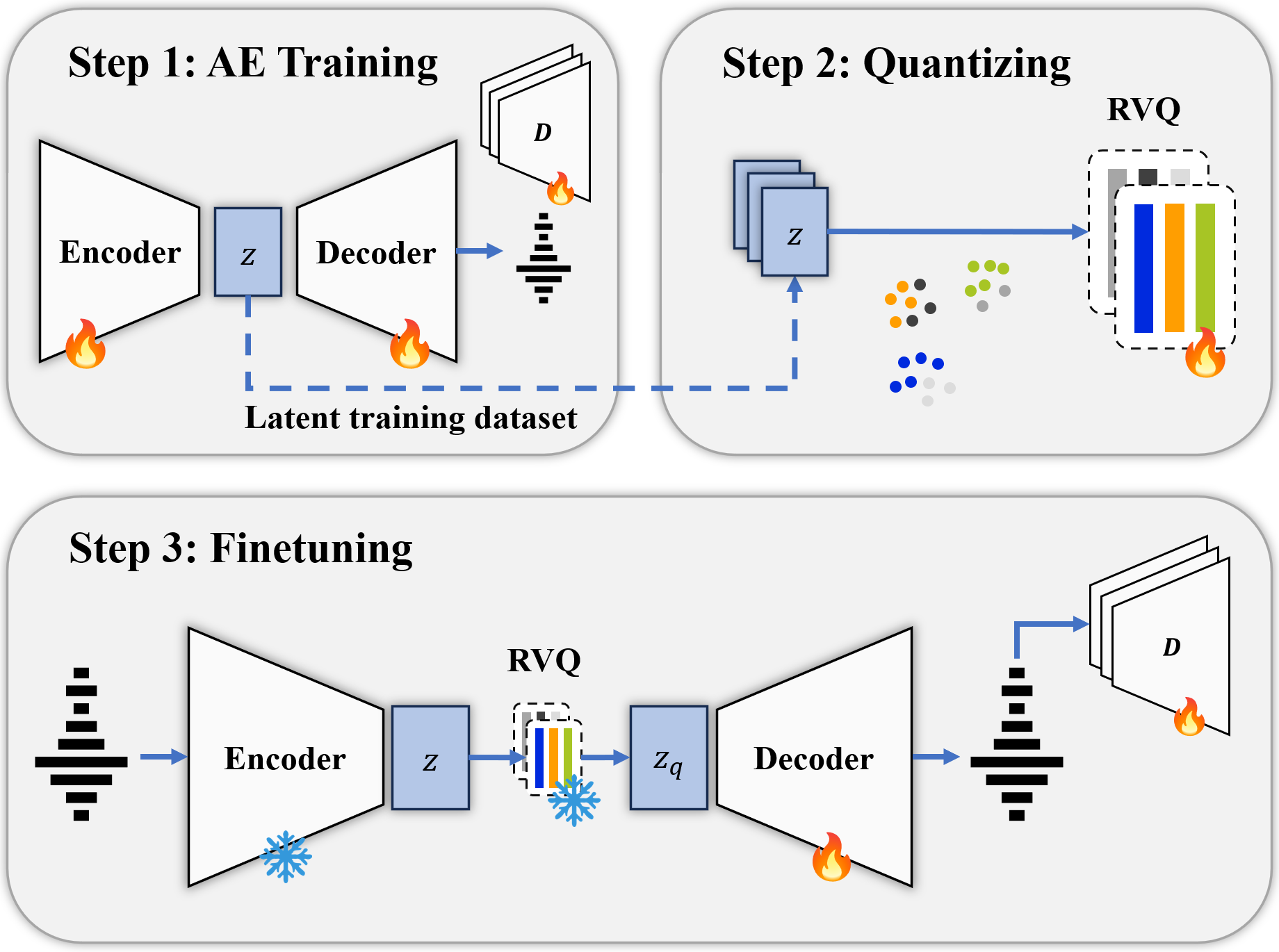
Training procedure of QINCODEC with offline quantization: First, we train a continuous compression model with spectral
and adversarial losses. Next, we quantize the bottleneck latent vec-
tors into discrete embeddings. We then finetune the decoder on the
quantized representations
Experiments and results
The tables below provide audio clips for evaluating the reconstruction quality of our model in comparison to the baselines presented in the paper. Some differences between audio samples may be subtle, so we recommend using headphones for an accurate assessment.